《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data 》论文总结
1.背景
DSSM是Deep Structured Semantic Model的缩写,即我们通常说的基于深度网络的语义模型,其核心思想是将query和doc映射到到共同维度的语义空间中,通过最大化query和doc语义向量之间的余弦相似度,从而训练得到隐含语义模型,达到检索的目的。DSSM有很广泛的应用,比如:搜索引擎检索,广告相关性,问答系统,机器翻译等。
2. DSSM
2.1简介
DSSM [1](Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
DSSM 从下往上可以分为三层结构:输入层、表示层、匹配层
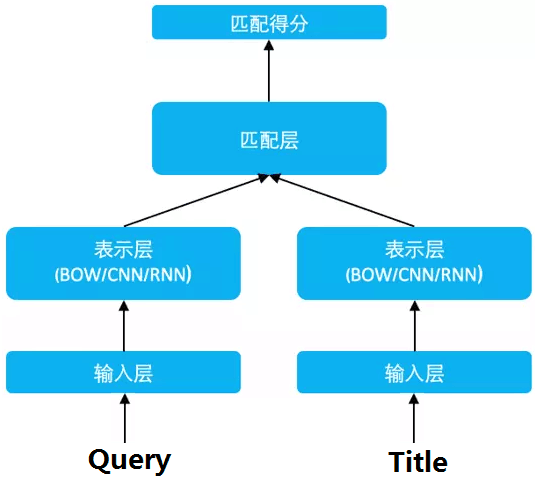
典型的DNN结构是将原始的文本特征映射为在语义空间上表示的特征。DNN在搜索引擎排序中主要是有下面2个作用:
- 将query中term的高维向量映射为低维语义向量
- 根据语义向量计算query与doc之间的相关性分数
通常, x用来表示输入的term向量, y表示输出向量, l_{i},i=1,…,N-1 表示隐藏层, Wi表示第 i层的参数矩
阵, bi表示 第 i个偏置项。

我们使用 tanh作为输出层和隐藏层的激活函数,有下列公式。

在搜索排序中,我们使用 Q来表示一个query, D来表示一个doc,那么他们的相关性分数可以用下面的公式衡量:

其中, yQ与 yD是query与doc的语义向量。在搜索引擎中,给定一个query,会返回一些按照相关性分数排序的文档。
通常情况下,输入的term向量使用最原始的bag of words特征,通过one-hot进行编码。但是在实际场景中,词典的大小将会非常大,如果直接将该数据输入给DNN,神经网络是无法进行训练和预测的。因此,在DSSM中引入了word hashing的方法,并且作为DNN中的第一层。
2.2 word hashing
word hashing方法是用来减少输入向量的维度,该方法基于字母的 -gram。给定一个单词(good),我们首先增加词的开始和结束部分(#good#),然后将该词转换为字母
-gram的形式(假设为trigrams:#go,goo,ood,od#)。最后该词使用字母
-gram的向量来表示。
这种方法的问题在于有可能造成冲突,因为两个不同的词可能有相同的 -gram向量来表示。下图显示了word hashing在2个词典中的统计。与原始的ont-hot向量表示的词典大小相比,word hashing明显降低了向量表示的维度。

2.3 DSSM的学习
点击日志里通常包含了用户搜索的query和用户点击的doc,可以假定如果用户在当前query下对doc进行了点击,则该query与doc是相关的。通过该规则,可以通过点击日志构造训练集与测试集。
首先,通过softmax 函数可以把query 与样本 doc 的语义相似性转化为一个后验概率:

其中 gamma是一个softmax函数的平滑因子, D表示被排序的候选文档集合,在实际中,对于正样本,每一个(query, 点击doc)对,使用 (Q, D^{+}) 表示;对于负样本,随机选择4个曝光但未点击的doc。
在训练阶段,通过极大似然估计来最小化损失函数:

其中 ![]() 表示神经网络的参数。模型通过随机梯度下降(SGD)来进行优化,最终可以得到各网络层的参数
表示神经网络的参数。模型通过随机梯度下降(SGD)来进行优化,最终可以得到各网络层的参数 ![]() 。
。
3.总结
DSSM的提出主要有下面的优点:
- 解决了LSA、LDA、Autoencoder等方法存在的一个最大的问题:字典爆炸(导致计算复杂度非常高),因为在英文单词中,词的数量可能是没有限制的,但是字母
-gram的数量通常是有限的
- 基于词的特征表示比较难处理新词,字母的
- 使用有监督方法,优化语义embedding的映射问题
- 省去了人工的特征工程
- 传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
缺点:
- word hashing可能造成冲突
- DSSM采用了词袋模型,损失了上下文信息
- 在排序中,搜索引擎的排序由多种因素决定,由于用户点击时doc的排名越靠前,点击的概率就越大,如果仅仅用点击来判断是否为正负样本,噪声比较大,难以收敛(DSSM 是弱监督模型)
- DSSM 是端到端的模型,虽然省去了人工特征转化、特征工程和特征组合,但端到端的模型有个问题就是效果不可控。
对于中文而言,处理方式与英文有很多不一样的地方。中文往往需要进行分词,但是我们可以仿照英文的处理方式,将中文的最小粒度看作是单字(在某些文献里看到过用偏旁部首,笔画,拼音等方法)。因此,通过这种word hashing方式,可以将向量空间大大降低。